Configure the Connection Settings
When exporting pages with images and loading other resources, the exporter may need to open HTTP(S) connections to the current Confluence instance. To do this the URL of the Confluence instance must be detected. However the automatic resource loading URL detection that is currently used does not work perfectly in several more complex scenarios and depending on reverse proxy configuration.
To configure the connection settings:
- Click the cog icon at top right of the screen and select General configuration.
The Confluence Admin screen is displayed. In the Scroll Word Exporter section, click Connection Settings.
The Connection Settings are displayed.Click Edit and select the wanted connection setting:
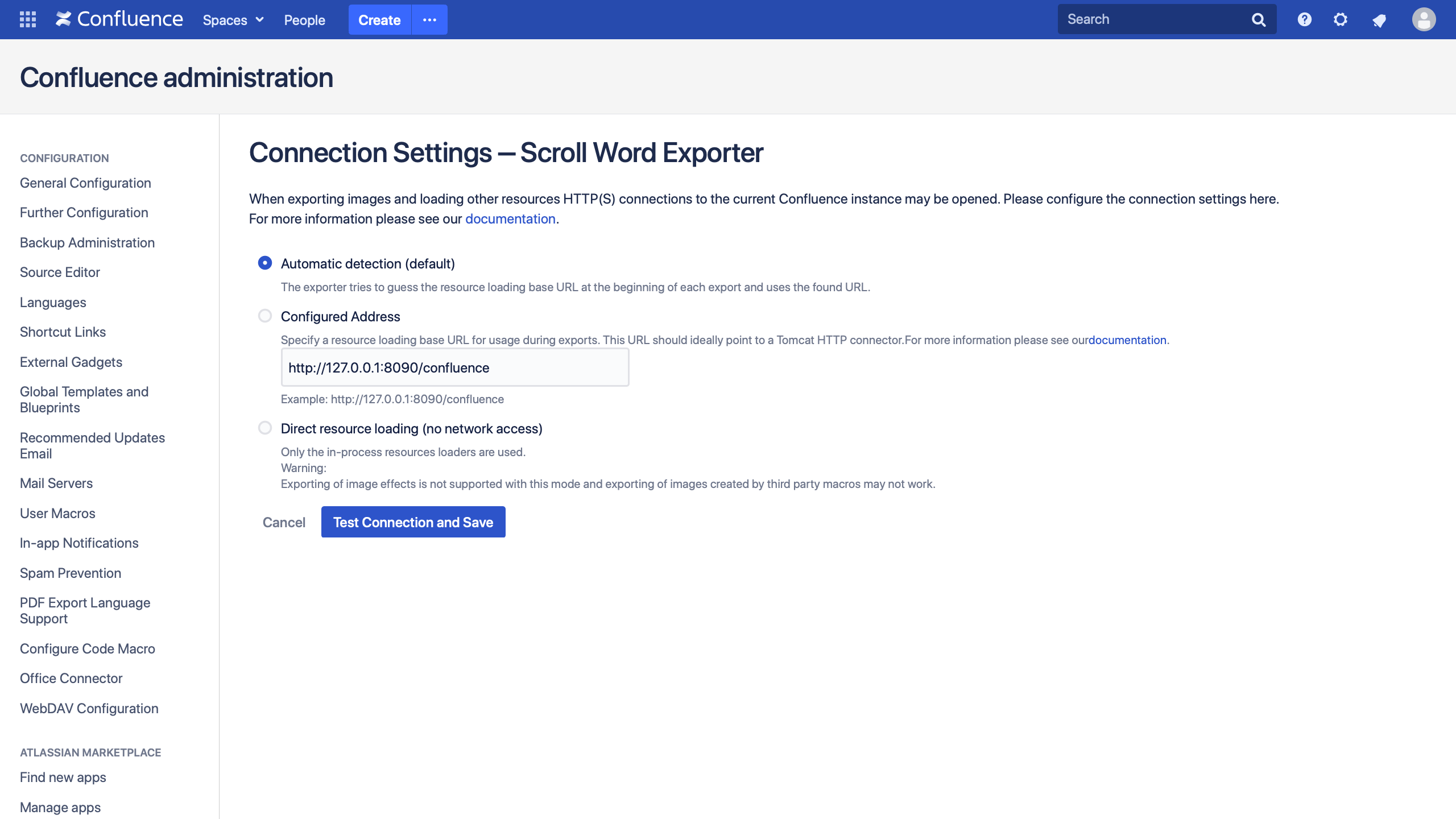
- Automatic detection (default value):
The exporter tries to guess the resource loading base URL at the beginning of an export and uses the found URL. This is the current approach. - Configured URL:
A base URL configured by an administrator is used. You can directly point to a tomcat connector here.
- No HTTP based resource loading:
Only the in-process resource loaders are used. When this option is selected no image effects are supported. The integration with Scroll Versions will not consider this setting as it can not work without it.
- Automatic detection (default value):
Click Test Connection and Save.
The connections is tested.
If it is tested successfully, the new setting is saved. If the connection fails, a error message is displayed:
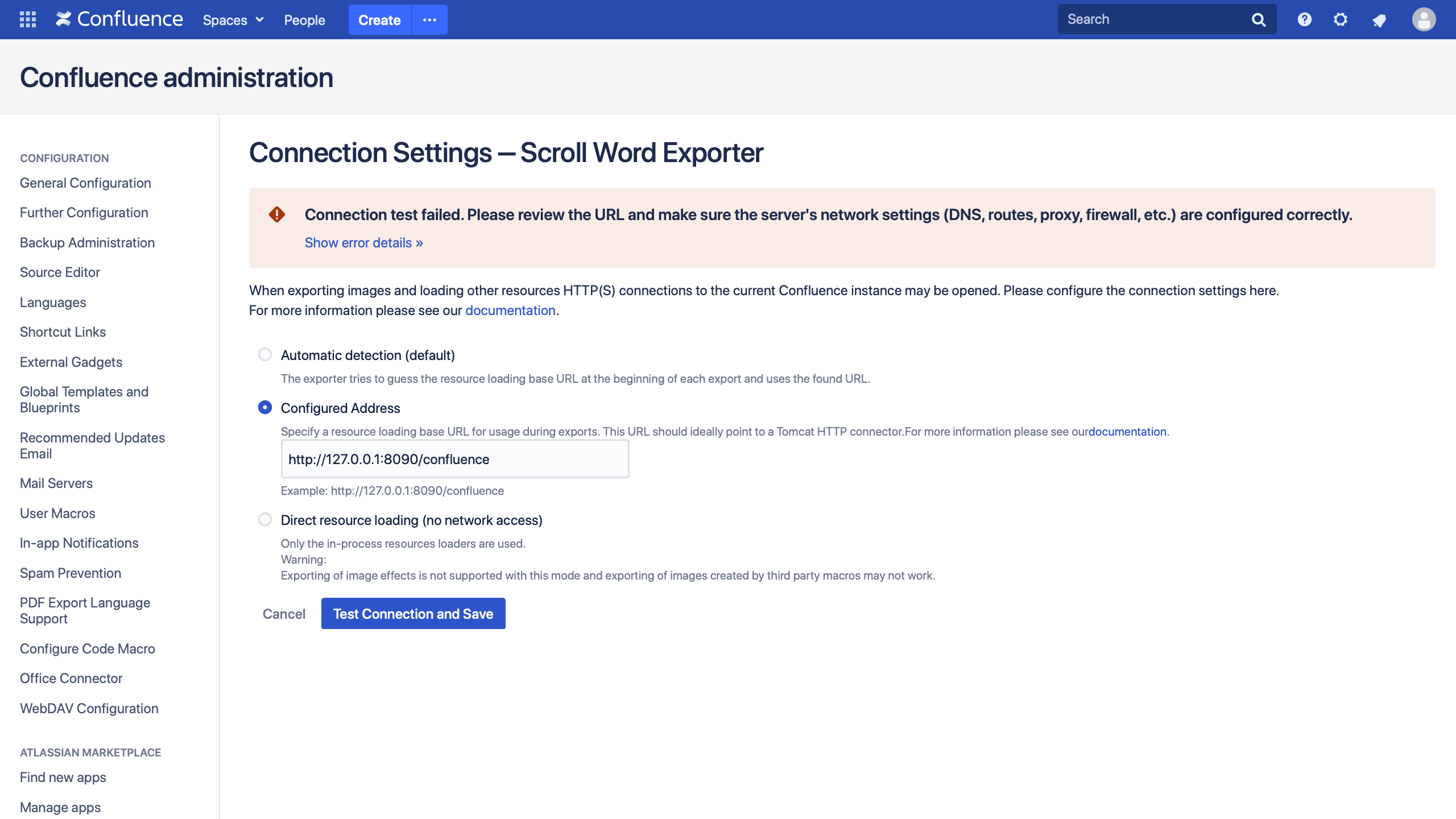
Please click Show error details for further details about the problem. If the given information does not help you, please contact help@k15t.com and send the whole code of the error, a Support ZIP and as much details about your network settings as possible.
Info
Please check your firewall configuration before contacting the K15t support and make sure that the firewall permits access to the configured URL or Confluence base URL.
Common Scenarios
Confluence behind Reverse Proxy
If Confluence is running behind a reverse proxy like nginx or Apache that reverse proxy might change the request URL before passing the request along to Confluence.
In that case you'll find an entry similar to the following in your Confluence log:
2014-07-25 09:01:09,687 DEBUG [pool-10-thread-1] [scroll.core.io.Resource] getContentAsStream Loading resource from http://10.252.207.1:28080/rest/scroll-versions/1.0/export-pagetree?pageId=557227&versionId=0AFCCF010144320CEFCFF2EE0D6B242A&variantId=all&pageSelectionStrategyId=com.k15t.scroll.scroll-pdf:alldescendants&pageSelectionStrategyProperties=%7B%7D
2014-07-25 09:01:09,696 WARN [http-28080-3] [auth.trustedapps.filter.TrustedApplicationFilterAuthenticator] authenticate Failed to login trusted application [confluence:16295870] due to bad URL signature. Received protocol version [2]. Required protocol version [2]This happens because the authentication token which is sent in a request header contains a signature of the request URL. If the reverse proxy changes the URL, the token is no longer valid and the request can not run with the authentication context of the user that started it.
To use the Scroll Exporter with Confluence behind a Reverse Proxy:
First try if using the Confluence base url as configured URL works for you. If not proceed with the following steps.
In the Tomcat
server.xmlfile, find the HTTP connector that your reverse proxy forwards to.If it contains one of
proxyNameorproxyPortattributes you need to create a separate connector without those attributes, for example:CODE<Connector port="8899" connectionTimeout="20000" redirectPort="8443" maxThreads="200" minSpareThreads="10" enableLookups="false" acceptCount="10" debug="0" URIEncoding="UTF-8" protocol="org.apache.coyote.http11.Http11NioProtocol" />- If not, then the existing connector can be reused.
- If you want to limit the exposure of the connector to a particular network interface, e.g. loopback, you can set the
addressattribute on the connector. e.g.address="127.0.0.1". - In the Scroll Exporter Connection Settings, use a configured URL that directly points to the connector.
Add the same context path (e.g./confluence) to the address that has been specified in the confluence base url (usually empty)
For example if the Tomcat HTTP connector is listing on port 8899 and there is no context path, set this URL:http://127.0.0.1:8899 - Make sure the firewall permits the access.
Confluence using HTTP Proxy for Outgoing Network Traffic
If the Confluence Java process is configured to use a HTTP proxy for outgoing connections, you may run into problems if that proxy requires authentication.
To use the Scroll Exporter with a HTTP Proxy:
- Use a configured URL for resource loading.
- Configure an exception for the proxy usage, so requests to the configured URL are not using the proxy.
For example when using the configured URLhttp://127.0.0.1:8090use system properties like these:
-Dhttp.proxyHost=my.http.proxy -Dhttp.proxyPort=80 -Dhttps.proxyHost=my.secure.proxy -Dhttps.proxyPort=443 -Dhttp.nonProxyHosts=localhost|127.0.0.1More information:
- You can find further information about configuring System Properties in Confluence in the Atlassian Confluence documentation.
- You can find further information about the System Properties available for Proxy configuration in the Oracle Documentation.
Confluence Datacenter Installations
When running a clustered Confluence installation you should setup an additional Tomcat HTTP connector on each cluster node:
<Connector port="8899" connectionTimeout="20000" redirectPort="8443"
maxThreads="200" minSpareThreads="10"
enableLookups="false" acceptCount="10" debug="0" URIEncoding="UTF-8"
protocol="org.apache.coyote.http11.Http11NioProtocol" />- Adapt the port number to your needs.
- Make sure that the connector contains neither
proxyNamenorproxyPortattributes.
After you've set up the connectors on each node and restarted them, you should configure this address for resource loading:
http://127.0.0.1:8899- Make sure to use the port you specified in the connector definitions.
- Add the same context path (e.g.
/confluence) to the address that has been specified in the confluence base url (usually empty). - It is important that every node resolves the specified address to itself, therefore we strongly recommend to use
127.0.0.1orlocalhost
SSO
In case you are using SSO, you might have to add a "whitelist" rule to the SSO service to pass on the authentication to Confluence in case HTTP request has a header with name "Scroll-Resource-Loading".